本文共 1518 字,大约阅读时间需要 5 分钟。
欧洲航天局科学数据中心(the European Space Agency Science Data Center,简称ESDC)利用TimescaleDB扩展切换到用PostgreSQL来存储他们的数据。ESDC的各种数据,包括结构化的、非结构化的和时间序列指标在内接近数百TB,还有使用开源工具查询跨数据集的需求。
\\ESDC收集来自他们每一个空间任务的海量数据(),并把这些数据提供给的团队使用。包括空间任务和卫星的元数据,以及在空间任务执行期间生成的数据,这些数据都可以是结构化的,也可以是非结构化的。生成的数据包括地理空间和时间序列数据。因为需要能够使用现成的、开源工具来分析数据,所以在选择数据存储解决方案时,对数据集的交叉运用就成了一个需求项 。团队希望摆脱像Oracle和Sybase这样的传统系统。
\\因为的成熟,以及对各种数据类型和非结构化数据的支持,ESDC团队已经确定使用PostgreSQL。除了这些例行要求外,ESDC也需要存储和处理地理空间和时间序列数据。地理空间数据是那些附有位置信息的数据,比如行星在天空中的位置。这必须在不使用不同类型或数据源的不同数据存储的情况下完成。之所以决定迁移到PostgreSQL,是因为它支持这种处理的扩展机制。PostgreSQL针对JSON和全文本搜索有原生支持。、和扩展运行ESDC使用常规SQL来运行基于位置的查询以及更专业的分析。
\\对于像这样的任务产生的时间序列数据,PostgreSQL还必须高效且可扩展地存储它们。这对写入速度要求很低,因为收集到的数据存储在本地的卫星上,“用于每天的地面站通行期间的稍后下行链路”,并分批次插入数据库。但是,针对这个数据库的查询,必须支持结构化的数据类型、数据集之间的ad-hoc匹配和高达数百TB的大型数据集。
\\目前,还不清楚哪些特定的时间序列数据库得到了评估,但是,该团队没有选择其中任何一个,因为他们已经将SQL标准化为首选的查询语言,并把PostgreSQL作为平台,因为它满足了他们的其他要求。一些可以把时间序列数据存储在PostgreSQL上。它最近的分区特性试图解决这样的问题:将大表索引保存在内存中,并在每次更新时将其写入磁盘,方法是将表分割成更小的分区。当按时间进行分区时,分区也可以用于存储时间序列数据,遵循着这些分区上的索引。ESDC存储时间序列数据的时候,遇到了性能问题,于是转而使用名为的扩展。
\\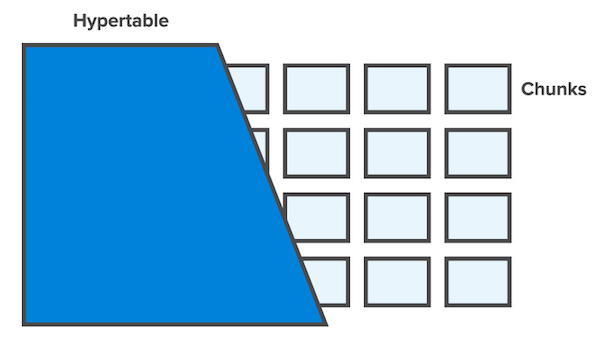
图片来源: https://blog.timescale.com/when-boring-is-awesome-building-a-scalable-time-series-database-on-postgresql-2900ea453ee2
\\TimescaleDB使用名为的抽象来隐藏跨多个维度(如时间和空间)的分区。每个hypertable被分成“块(chunk)”,每个块对应一个特定的时间间隔。块的大小是一定的,因此,用于表索引的所有B树结构都能够在数据插入数据库期间驻留内存,类似于PostgreSQL进行分区的方式。索引是根据时间和分区关键字自动产生的。可以针对任意“”进行查询,就像其他时间序列数据库允许查询一样。
\\TimescaleDB和其他分区工具(如)的区别之一是。尽管,与基于PostgreSQL 10 分区的解决方案和相比,TimescaleDB有更高的性能基准,但人们一直。在撰写本文时,TimescaleDB的集群部署仍处于开发阶段。
\\TimescaleDB是的开源软件。
\\阅读英文原文:
\\感谢对本文的审校。
转载地址:http://suoux.baihongyu.com/